






Introduction
ChatGPT is a massive artificial intelligence (AI)-based model that has taken the world by storm [1]. In just over 5 days, ChatGPT recorded over 1 million users, achieving a milestone that Facebook took 10 months to reach, Instagram accomplished in 2.5 months, and Netflix achieved in 41 months. This model was built upon the foundation of a large language model (LLM), and was trained on a huge amount of text data, exceeding 45 terabytes [2]. LLM utilize deep neural networks to analyze and generate text based on data inputted into the model. While ChatGPT has yet to be trained specifically for medical use in Poland, efforts have already commenced in the United States to use this tool in more efficient patients’ descriptions, medical education, and retrieval of medical information [3].
In the field of radiology, AI has primarily been employed for automating the generation of imaging study descriptions and image analysis. However, these applications, though more advanced in Western countries, are still in testing phase in Poland. Nevertheless, ChatGPT has gained interest in its potential applications in education, differential diagnosis, and disease classification, utilizing LLM capabilities [4].
ChatGPT uses a deep learning model to recognize patterns and relationships between words. Its functionality relies on extensive training databases to generate human-like responses. However, it is important to note that the model’s reactions can sometimes be inaccurate or incorrect. Despite this, an intriguing study evaluating ChatGPT performance on United States medical licensing exam (USMLE) yielded surprising results. The model achieved a score of 60%, equivalent to passing the exam [5].
Apart from the broad applicability of LLM and ChatGPT, on which it is based, its use in medicine and radio-logy has not yet been defined. National specialty examination (NSE) aims to comprehensively assess the knowledge, reasoning abilities, and decision-making skills of specialist trainees in specific clinical scenarios. Our study aimed to evaluate ChatGPT’s effectiveness in answering radiological NSE questions, and analyze its strengths and weaknesses in comparison with human cognition.
Material and methods
Examination and questions
This prospective study was conducted from May 5th, 2023 to May 24th, 2023. The focus of the study was one specialty exam in radiology and diagnostic imaging (Spring, 2023), which was randomly selected from available exams in the question archive database of Medical Examinations Center in Lodz, Poland. The selected exam comprised of 120 single-choice questions, each having one correct answer and four distractors (wrong answers). One question was excluded by the Board of Examiners, as it was not in line with current knowledge. Therefore, a total of 119 questions were analyzed.
To ensure comprehensive analysis, all questions were classified according to Bloom’s taxonomy [6,7]. The classification included memory questions, comprehension, and critical thinking questions as well as further sub-divisions, such as calculations and classifications, description of imaging results, disease-related questions, and clinical management questions. Additionally, each question was cate-gorized as physical, clinical, or topography-related. Two independent researchers performed the classification, and any disagreements were resolved by a third independent researcher. Inter-observer agreement was evaluated using a statistical test, with Cohen’s coefficient of 0.95 (agreement, 97.9%), indicating near-perfect agreement [8].
Data collection and analysis
Prior to presenting the questions, ChatGPT-3.5 was provided with exam rules, including number of questions, number of answer options, and number of correct answers. Furthermore, after each question, an additional query was posed to ChatGPT, asking, “On a scale of 1 to 5, how confident are you in this answer?” This was done to assess ChatGPT’s level of confidence in its chosen response. The scale was defined as follows: 1 represented “definitely not sure”, 2 “not very sure”, 3 indicated “almost sure”, 4 “very sure”, and 5 meant “definitely sure”. Each question was inputted into ChatGPT, and all chat interactions were documented (see Supplement 1). To maintain consistency with the content of exam questions, the chat dialogue was conducted in Polish.
Statical analysis
The results obtained from ChatGPT were compared with correct answers and statistics published by the Medical Examinations Center in Lodz. The evaluation focused on determining the percentage of correct answers provided by ChatGPT. The percentage of correct answers provided by ChatGPT for different question types and sub-types was also compared. The difficulty of questions that were answered correctly and incorrectly by ChatGPT was also analyzed.
To assess the significance between distributions of correct and incorrect answers, question type, and other qualitative variables, Pearson χ2 test was applied. Shapiro-Wilk test was used to evaluate the distribution of quantitative variables, such as question difficulty and RBPI (relative Bloom’s proficiency index). For comparing quantitative variables between groups, Mann-Whitney U test was employed. R Studio (Integrated Development for R. Studio, PBC, Boston, MA, USA) was used for all statistical analyses.
In addition, to compare the confidence level of responses between correct and incorrect answers, Mann-Whitney U test was applied. P-values of less than 0.05 were considered significant.
Results
In the radiology NSE, ChatGPT received an overall failing grade, scoring 52%. The passing threshold for the exam was set at 60% (Table 1). For statistical analysis, specific groups of questions, on which ChatGPT was assessed were selected. These groups included “critical thinking” and “knowledge” questions. The “critical thinking” group was further divided into sub-categories, such as “clinical management”, “describing imaging studies”, “calculating and classifying”, and “disease-related” questions. The questions were also categorized into three types, such as “clinical”, “physical”, and “topography”.
Table 1
Percentage of correct and false answers submitted by ChatGPT in the whole test
| Correct answer | Number | Percentage |
|---|---|---|
| Yes | 63 | 0.52940 |
| No | 56 | 0.47060 |
ChatGPT’s performance in the exam was as follows: for “critical thinking” questions, it scored 55.56% (50 out of 90), and for “knowledge” questions, it scored 44.83% (13 out of 29) (Table 2). In the sub-categories, ChatGPT scored 75% (6 out of 8) for “clinical management” questions, 62.86% (22 out of 35) for “clinical examination” descriptions, 51.43% (18 out of 35) for “disease-related” questions, 33.33% (4 out of 12) for “calculations and classifications”, and 33.33% (3 out of 9) for “topography-related” questions (Table 3). Regarding question types, ChatGPT correctly answered 54.55% (54 out of 99) of clinical questions and 54.55% (6 out of 11) of physical questions (Table 4). No significant differences were observed in the percentage of correct answers among questions types and sub-types (χ2 test; Tables 2-4).
Table 2
Distribution of correct/false answers and types of questions, χ2 test (p = 0.31)
| Question type | Correct answer | |
|---|---|---|
| Yes, n (%) | No, n (%) | |
| Comprehension and critical thinking | 50 (55.56) | 40 (44.44) |
| Memory | 13 (44.83) | 16 (55.17) |
Table 3
Distribution of correct/false answers and types of questions, χ2 test (p = 0.20)
Table 4
Distribution of correct/false answers and types of questions, χ2 test (p = 0.47)
| Question type | Correct answer | |
|---|---|---|
| Yes, n (%) | No, n (%) | |
| Physical | 6 (54.55) | 5 (45.45) |
| Clinical | 54 (54.55) | 45 (45.45) |
| Topography | 3 (33.33) | 6 (66.67) |
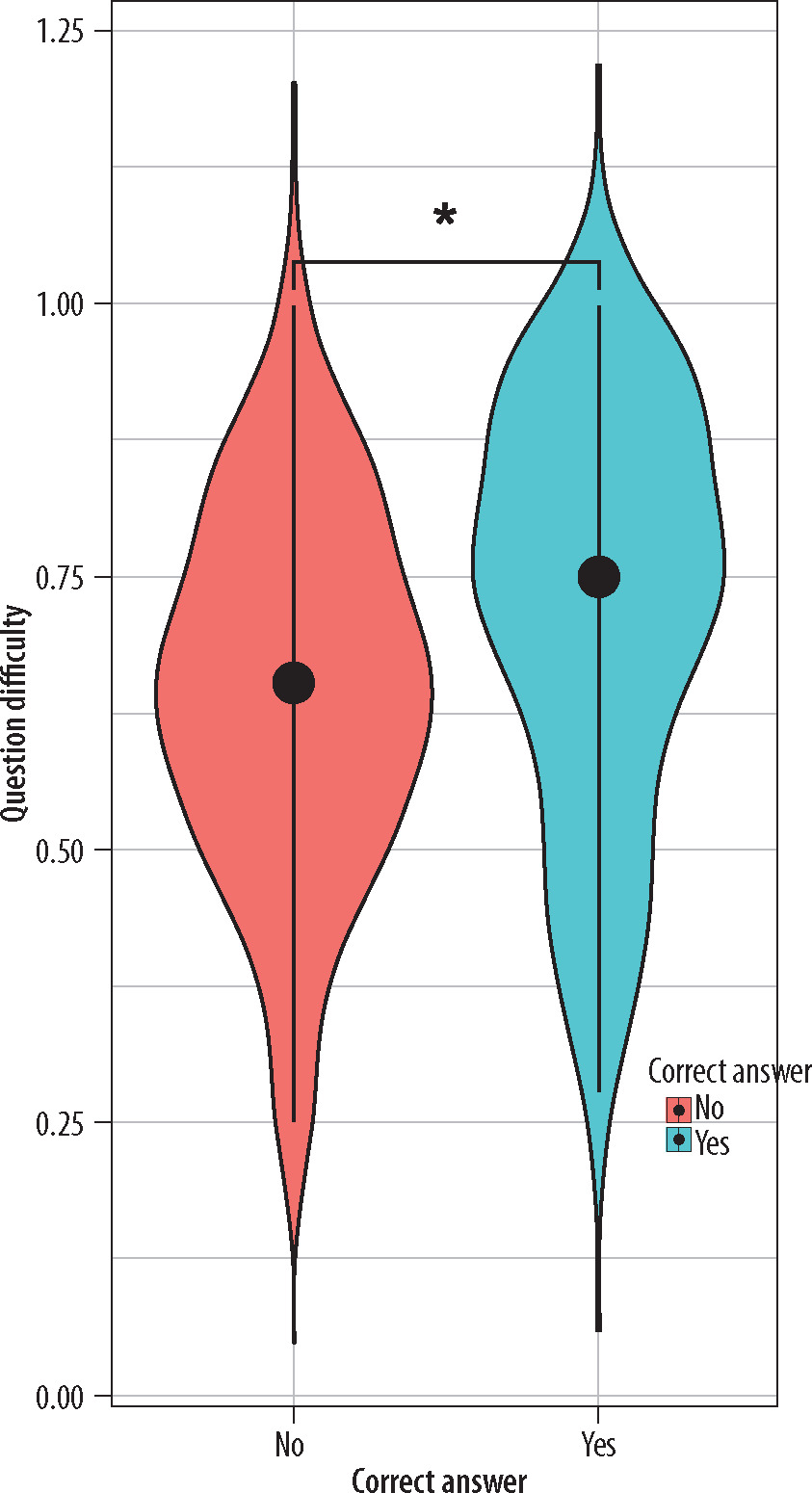
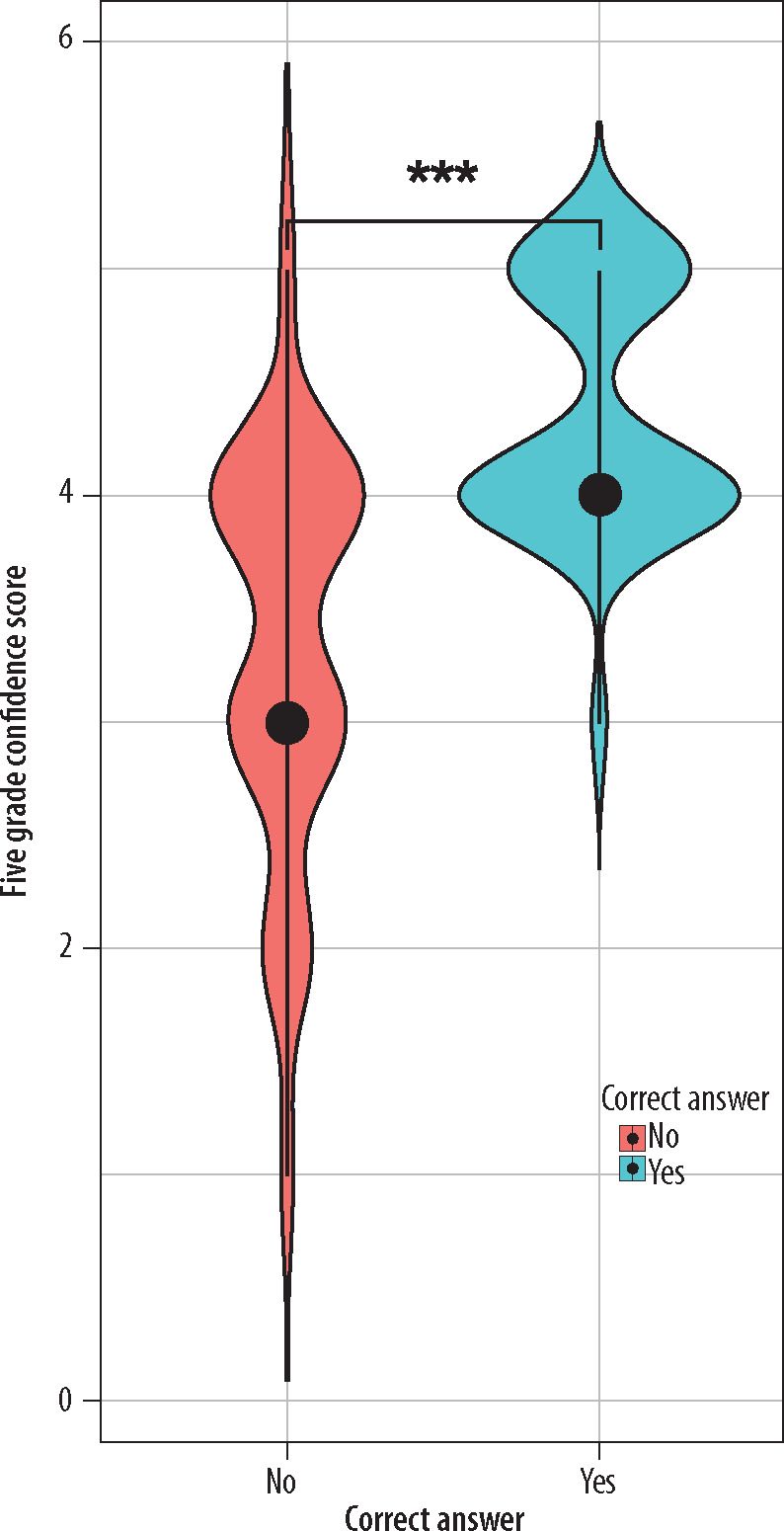
A significant difference in the difficulty index was observed between questions that ChatGPT answered correctly and those answered incorrectly. The difficulty index (Table 5, Figure 1) was significantly higher for questions that ChatGPT answered correctly. Additionally, the confidence index between correct and incorrect answers was analyzed (Table 4, Figure 2), revealing that questions answered correctly by ChatGPT had a higher confidence index. No correlation was observed between the question difficulty index and the certainty of answer on a five-point scale. There was no association between the type of question and the frequency of correct answers submitted by ChatGPT.
Table 5
Comparison of questions difficulty, and five-grade confidence score between correctly and incorrectly answered questions by ChatGPT (Mann-Whitney U test)
| Correct answer | False answer | p-value | |||||
|---|---|---|---|---|---|---|---|
| Median | Q1 | Q3 | Median | Q1 | Q3 | ||
| Questions difficulty | 0.75 | 0.61 | 0.89 | 0.65 | 0.54 | 0.78 | < 0.05 |
| Five-grade confidence score | 4.00 | 4.00 | 5.00 | 3.00 | 3.00 | 4.00 | < 0.001 |
Discussion
The specialist examination in radiology and imaging diagnostics is a crucial assessment for individuals seeking to complete their specialist training and become specia-lists in this field of medicine. The examination comprises both practical and theoretical component. In Poland, a score of 60% or higher is considered a passing grade for the specialist examination in radiology and imaging diagnostics. However, if a candidate achieves a score of 75% or higher in the theoretical part, oral examination is waived. Similar qualification examinations are used in many countries worldwide. For instance, experiments similar to ours have been conducted in Canada and the United States.
In our study, ChatGPT performed significantly worse (52%) than in a study by Bhayana et al., who investigated the pass rate of the Canadian Royal College examination in diagnostic radiology [9]. This means that ChatGPT did not attain a score high enough to pass the exam. In our study, ChatGPT achieved a higher score on questions requiring critical thinking (55%) compared with questions needing knowledge (44%). However, it performed worse than in Bhayan et al. study, where it scored 84% on lower-order thinking questions and 60% on higher-order thinking questions (p = 0.002). It is quite remarkable that ChatGPT achieved superior outcomes in questions, which required critical thinking as opposed to questions needed knowledge. One explanation might be that the PES is the most difficult exam a potential radiologist will take, which makes PES questions very complex and difficult. It is possible that such a scenario may arise where a question requiring knowledge is structured in a highly intricate manner, resulting in inadequate responses. ChatGPT performed best on clinical questions (75%), but its performance was better in Bhayana et al. study (89%). Similarly, the AI model performed poorly on calculation and classification questions in both studies, achieving a score of 33% in our study and 25% in Bhayana et al. research. Moreover, theoretically, ChatGPT as an AI tool should exhibit superior performance in questions regarding calculation and classification. However, this was not the case in this instance. Many questions in this category required ChatGPT to classify complex and difficult radiological findings into many different categories, which resulted in very poor results. It performed better on physical questions in Bhayana et al. study (55% compared with 30% in our study). Conversely, it performed worse on clinical questions in the present study (55% compared with 73% in Bhayana et al.). Additionally, we observed that Chat-GPT consistently used certain language patterns to present its answers, which might have influenced user’s perception of correctness, even when the answer was incorrect.
A study by Gilson et al. [10] demonstrated that the latest version of the ChatGPT model outperformed pre-vious versions by 8.15% in answering questions from AMBOSS (a publicly available database of questions for medical students) and National Board of Medical Examiners (NBME) database. The study also found that logical reasoning for ChatGPT’s answer choices was present in 100% of the results from the NBME datasets, even when they did not align with the answer key.
In our study, we identified that questions, for which ChatGPT provided correct answer, had a significantly higher confidence index. Therefore, the confidence index can be considered a parameter indicating a higher likelihood of ChatGPT providing a correct answer (Figure 2). Discrepancies between the obtained results are likely attributed to differences in the quality, complexity, and specificity of the presented test questions as well as a potential language barrier since Polish is not the primary language for the ChatGPT model. It can be concluded that, given equal access to training resources and training time, the Polish specialist exam is significantly more challenging than the Canadian Royal College exam. Furthermore, it is reasonable to assume that if the Polish radiology textbooks recommended for studying for the specialty exam were more readily available in an online format, ChatGPT would be more likely to utilize the data from these textbooks in its training, therefore improving its ability to handle questions from the NSE.
Conclusions
Based on the presented results, it can be concluded that the performance of the ChatGPT model in passing the specialist in radiology and imaging diagnostics examination in Poland remains uncertain. In our experiment, the model did not achieve the minimum score required for a passing grade, although it came close in certain cate-gories. To truly assess the effectiveness of ChatGPT in successfully passing the specialty exam, further testing using official questions provided by the Centre for Medical Exa-minations is necessary.
When evaluating the usefulness of ChatGPT, factors such as, the level of difficulty of the exam, the specific types of questions that posed the greatest challenges, and the availability of recommended scientific sources for studying for the NSE, should also be taken into consideration. It is possible that future versions of the ChatGPT model may perform better in addressing requirements of the NSE, but currently, there is no evidence to support this claim. Further research and testing of ChatGPT on the passing rates of state examinations in radiology are necessary to gain a more comprehensive understanding of its capabilities.