Introduction
Glioblastoma, grade IV glioma according to the World Health Organization classification, is the most common malignant tumour of the central nervous system in adults [1]. Imaging techniques such as computed tomography (CT) and magnetic resonance imaging (MRI) are routinely utilized for diagnosis, characterization, surveillance, and post-treatment management of patients with glioblastoma tumours [2,3]. However, MRI is the gold standard imaging technique for visualizing glioblastoma tumours owing to its superior soft tissue contrast compared to a CT scan [4]. Over the last 3 decades, MRI has been used as the standard of care radiographic characterization of Glioblastoma tumours. Therefore, the MR scan plays a central role in evaluating glioblastoma. Multiple MRI sequences such as T1-weighted (T1w) and contrast-enhanced (T1CE), T2-weighted (T2w), and T2-fluid-attenuated inversion recovery (T2-FLAIR) sequences can be simultaneously utilized for the segmentation of glioblastoma tumours [5]. Today, the standard treatment for glioblastomas is a combination therapy including surgery, radiotherapy, and chemotherapy [6]. External beam radiotherapy (EBRT), as part of the multidisciplinary treatment, plays a critical role in the treatment of patients with glioblastoma tumours, and glioblastoma is one of the major indications for EBRT [7,8].
Delineation of target (i.e. tumour) volumes and organs at risk (OARs) is one of the most tedious, challenging, and time-consuming tasks in the radiotherapy treatment planning process [9]. In clinical practice, this procedure is still done manually in 2-dimensional (2D) slices of CT or MR images by radiation oncologists. However, manual segmentation is still considered the gold standard in radiotherapy planning – manual contouring of brain tumours suffers from high inter-rater and intra-rater variability owing to human error, observer bias, and varying experience of the radiation oncologists [10-12]. In this regard, automated contouring methods can be very useful for radiotherapy target volume delineation. Over the last decades, numerous automated machine learning algorithms have been developed for brain tumour segmentation [13] to substantially limit the time for target volume definition and to introduce a more consistent and reproducible standard for volume definition (i.e. avoiding the intra- and inter-observer variations) [14]. Currently available machine learning-based auto-segmentation methods can be mainly categorized into traditional methods and deep learning methods [15,16]. Deep learning, a branch of machine learning, with multi-layered neural networks is capable of processing large datasets to provide automated solutions without the need for hand-crafted features [9]. Deep convolutional neural networks (CNNs), as a deep learning method, outperform alternative methods, i.e. classic machine learning methods, in a wide range of applications [17-20], including medical image segmentation [21,22]. Therefore, deep CNNs can be considered as the state-of-the art computer-assisted method for segmentation.
To date, although a number of studies have developed deep learning-based methods for the automatic segmentation of brain tumours, the main focus of most research endeavours was on using CNN-based networks for automated delineation of the gross tumour volume (GTV) on MR images [23-26]. Hence, the purpose of this study was to develop a tool for automatic segmentation of clinical tumour volume (CTV) in radiotherapy for patients with Glioblastoma on brain MRI using a deep CNN model. We trained our 2D deep CNN-based MRI-based auto-contouring algorithm on the Multimodal Brain Tumour Segmentation (BraTS) 2019 challenge dataset for GTV segmentation and assessed its performance using the same dataset. This pre-trained CNN model using BraTS 2019 dataset was fine-tuned with an independent clinical dataset to perform the CTV segmentation. Furthermore, we also assessed the algorithm on the independent clinical dataset, and the agreement between automated segmentations and radiation oncologist contours as the ground truth was assessed using the dosimetric and geometric metrics. The novelty of this study lies in the following: (1) modification of the SegNet architecture using deep supervision and residual blocks on skip connections, (2) CTV segmentation of glioblastoma tumours, and (3) generation of segmentation masks directly on CT images under the guidance of MR images.
Material and methods
Dataset
In this study, the primary experimental data used are from the BraTS 2019 challenge dataset [5,27,28]. The BraTS 2019 training data consists of 259 multi-modal brain MR studies, consisting of glioblastoma patients. There are 4 brain MRI sequences for each sample, which include T1w, post-contrast T1w (T1ce), T2w, and FLAIR sequences. These MR images have the size of 240 × 240 × 155 and resolution of 1 × 1 × 1 mm3. All MRI images have been segmented manually by experts into 4 main classes (i.e. enhancing tumour [ET], necrosis and non-enhancing tumour [NEN], oedema [OD], and healthy tissue), and experienced neuroradiologists approved their annotations. Each tumour was segmented into oedema, necrosis, and non-enhancing tumour and active/enhancing tumour. Herein, only T1 and T1c MRI sequences on the tumour core sub-region (i.e. ET + NEN) were used.
In this work, a total of 80,290 (= 259 volumes × 155 slices per volume × 2 different sequences) sets of glioblastoma slices were extracted from the BraTS 2019 dataset. We performed our experiments on the BraTS 2019 training dataset in which 80% were used for training, 10% for validation, and 10% for testing. Moreover, an independent clinical dataset from Imam Khomeini Hospital Complex (Tehran, Iran) was also used to evaluate the performance of the proposed method. This independent clinical dataset contained both CT and MRI scans of 52 subjects with glioblastoma (age > 18 years) treated with 3-dimensional conformal radiothe-rapy (3DCRT). Figure 1 gives an overview of the approach used for the CTV segmentation of glioblastoma.
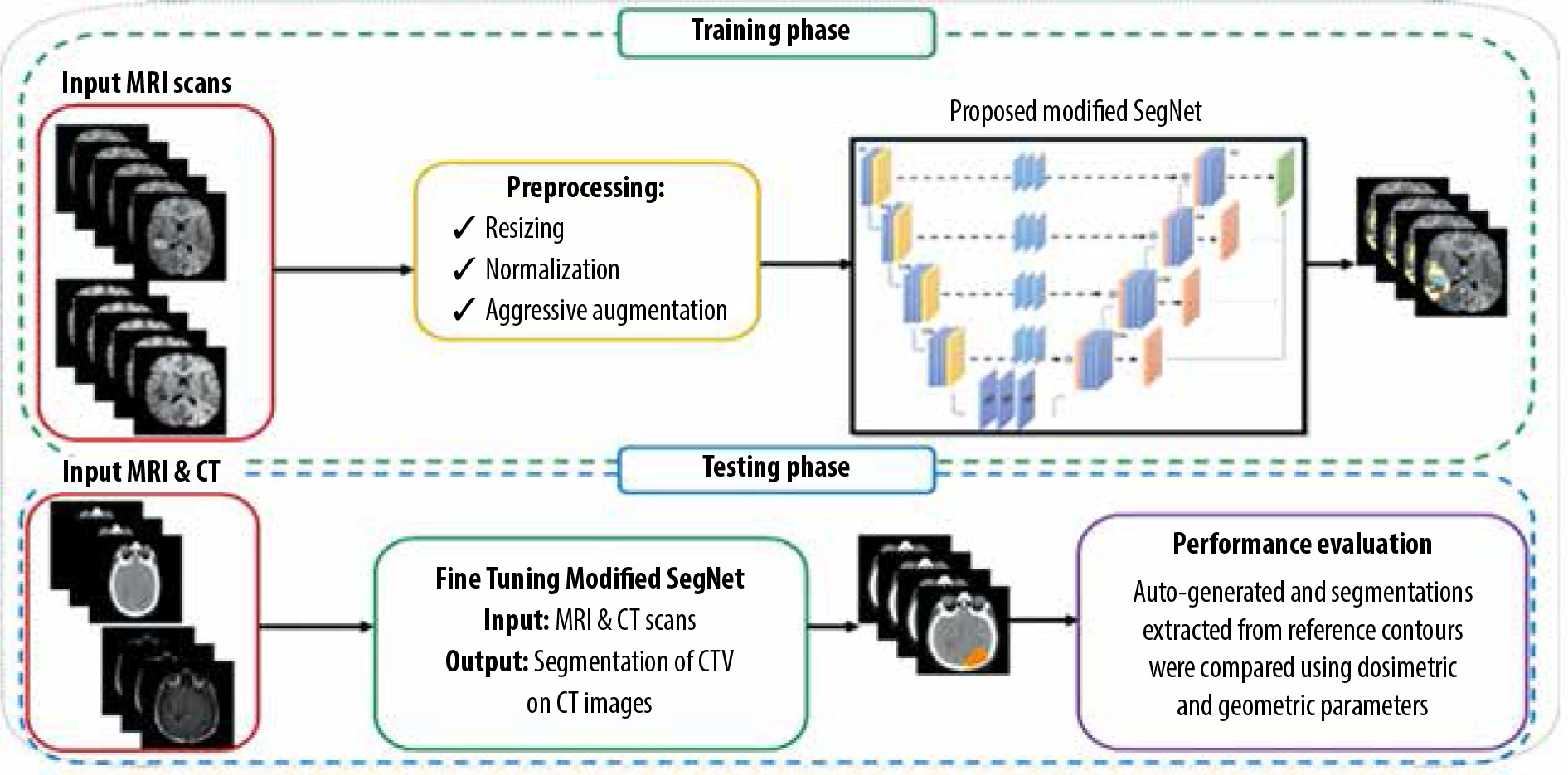
Data preprocessing and augmentation
In this stage, a set of preprocessing on MR images was implemented, which included skull-stripping, resizing to 256 × 256, normalization of pixel values to a range of 0 and 1, and volume clipping. In this study, data augmentation methods including flipping left and right and brightness tuning were also used. Moreover, brain pixel intensities were clipped with a window of [1-99%]. All the pixel intensities in all images were normalized into unit variance and zero mean. During training process, elastic deformation with a probability of 30% was applied to the images. On the independent clinical dataset, we applied coach cropping.
Convolutional neural network model
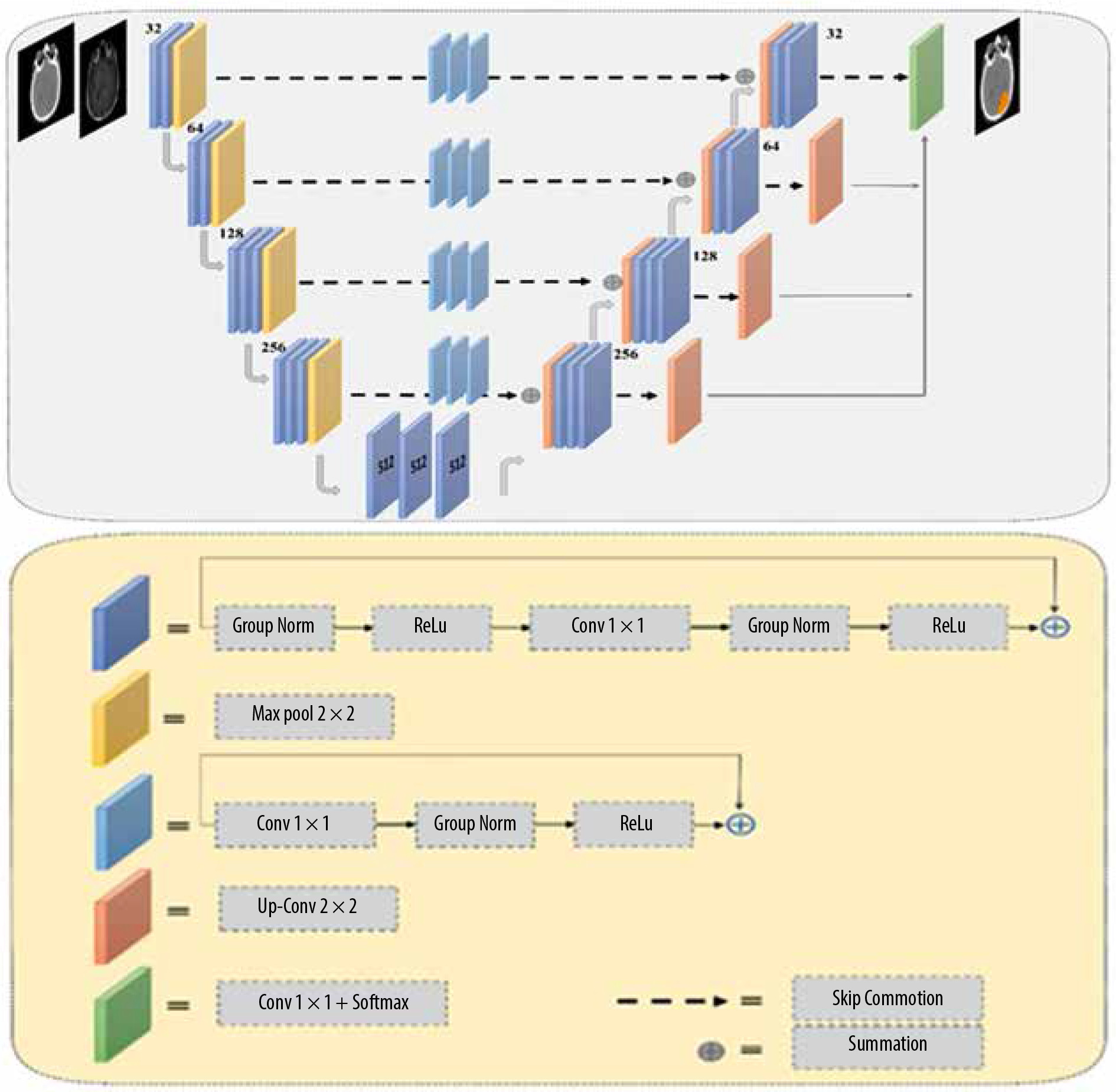
In this study, we applied a modified version of the semantic segmentation (SegNet) model, a deep, fully CNN architecture, which was originally proposed by Badrinarayanan et al. [29] for semantic pixel-wise segmentation. The SegNet model structure consists of an encoder network and a corresponding decoder network, followed by a final pixel-wise classification layer. The encoder network in SegNet has 13 convolutional layers, which are identical to the first 13 convolutional layers in VGG16 [30-32]. In the SegNet architecture, the fully connected layers of VGG16 were removed, and therefore the network parameter is significantly decreased and easier to train than many other recent models. The decoder network is considered as the key constituent of the SegNet architecture, which consists of a hierarchy of up-sampling decoders – one corresponding to each down-sampling encoder. Therefore, the decoder network also has 13 layers. In the SegNet model, deconvolution layers are not applied for up-sampling. Instead, the proper decoders use the max-pooling indices taken from the down-sampling path to up-sample the input feature maps. To overcome the gradient vanishing problem and reduce the time of convergence process, a deep supervision is used in the decoder side. Deep supervision leads to the generation of multiple segmentation maps at various resolution levels. In addition, deep supervisions act as strong regularizations for pixel classification accuracy and to learn critical texture features. The SegNet architecture employs skip connections to forward the feature maps from the encoder to the decoder network for better reconstruction at the network output. However, distinguishing between the useful information required for transferring from the encoder to the decoder blocks and the non-useful information is difficult. To resolve this issue, 3 residual blocks with a group normalization layer were applied to provide the global context of high-level features to assist the low-level features to obtain class category localization. In the end, the soft-max layer, as the final layer, classifies each pixel independently using the features input by the final decoder output. The network architecture used to segment clinical target volume of glioblastoma patients is shown in Figure 2.
Training
Initially, the SegNet model was trained on the BraTS 2019 training dataset for the gross tumour volume (GTV) segmentation of glioblastoma tumours. In this study, an independent clinical dataset consisting of CT and MRI scans from 52 glioblastoma patients was used, in which CTV contours of glioblastoma tumours were delineated on CT with guidance of MRI scans. Out of 52 glioblastoma patients, 37 were used for fine-tuning the trained network in the previous step, while the remaining 15 were used to evaluate the performance of the model. This independent clinical dataset was used to fine-tune the network architecture trained on the BraTS 2019. In other words, network fine-tuning was performed for CTV contours. In the fine-tuning step, to have the CT mask as the network output, both CT and MRI scans were used as input data and the corresponding CT masks were used as output labels. As a result, no CT/MRI image registration was applied for CTV contouring, which reduces contouring error. Dice loss as the loss function was adopted. We optimized Dice loss by the Adaptive Moment Estimation (Adam) optimizer, and utilized the initial learning rate of 0.01, batch size of 32, and epoch value of 200. Furthermore, a learning rate scheduler was used to adjust the learning rate during the training process by decreasing the learning rate after a set number of training epochs. We also applied data augmentation methods and a probability map. Our framework was implemented with the PyTorch framework and Torchvision library. All the experiments were conducted on the hardware of NVIDIA Tesla p100 GPU and 8 GB RAM. The training time of the SegNet architecture was about 13 hours.
Treatment planning
To investigate the impact of CNN-based contouring inaccuracies on dose-volume parameters, such as minimum, maximum, and mean dose of the CTV (Dmin, Dmax, Dmean, respectively) and dose to 98% of the CTV(D98%), treatment plans based on manual contours were gene-rated. Thus, 15 glioblastoma patients were retrospectively included in this work, as stated earlier. The retrospective T1w pre-treatment MR images and CT scans were used. The patients were scanned using a Siemens SOMATOM Sensation 16-Slice CT-scanner with a slice thickness of 3 mm. The patients were immobilized using a head mask. MR images were acquired on a GE 3.0 Tesla Discovery MR 750 scanner (GE Healthcare, IL, USA) using the head coil. Both CT and MRI images were imported into Eclipse v.13.0 (Varian Medical System Inc, Palo Alto, CA, USA) treatment planning software (TPS). An experienced radiation oncologist delineated CTV on post-contrast T1w MRI images. The CT/MRI brain registration was performed within the Eclipse TPS. Also, the auto-generated contours from SegNet architecture were transferred to the TPS to compute the above-mentioned dose-volume parameters and to compare them with the corresponding parameters derived from manual delineated contours, as the ground truth. All 3DCRT plans were generated in the Varian Eclipse TPS, using the AAA algorithm. All patients were treated with 3DCRT using a 6 MV photon beam (Varian Clinac-ix, Varian Medical System Inc, Palo Alto, CA, USA) with multi-leaf collimators. The prescription dose was 60 Gy in 30 fractions based on the ESTRO-ACROP guideline [27].
Evaluation metrics
In this study, 15 patients from the independent clinical test dataset were applied to assess the segmentation performance of the proposed model. The Dice similarity coefficient (DSC) and Hausdorff distance were employed to compute the geometric discrepancies between the manual delineated and auto-generated contours. The Dice score computes the overlap between the manual segmentations as the ground truth and the predicted contours. The Hausdorff distance evaluates the maximum distance between the surfaces of 2 contours. A smaller Hausdorff distance indicates lower discrepancy between 2 different segmentations. Also, the dosimetric discrepancies between the manual segmentations as the gold standard and auto-generated contours were evaluated using dose-volume parameters such as Dmin, Dmax, Dmean, and D98% for the CTV.
Statistical analysis
Statistical analysis was conducted using SPSS 22.0 software (SPSS, Chicago, Illinois). The normality of data distribution was investigated using the Kolmogorov–Smirnov test. The paired sample t-test was used to evaluate the level of significance of the measured parameters. A p-value ≤ 0.05 was considered statistically significant.
Results
The SegNet architecture achieved a Dice score of 88.6% for the tumour core class on selected test set the BraTS 2019 dataset. The segmentation using modified SegNet took about 100 s for an input CT images (i.e. approxima-tely 120-150 slices).
Figure 3 illustrates a comparison of manual versus automatic segmentation of CTV for 15 glioblastoma patients which used as the testing dataset in this study. As shown in Figure 3, most deep learning-based auto-segmented volumes are smaller than the expert radiation oncologist volumes. The mean ± standard deviation (SD) CTV volumes segmented manually and by the modified SegNet model were statistically significantly different: 73.5 ± 48.3 cc and 63.0 ± 38.2 cc, respectively (p = 0.004). Axial T1w MRI images of a representative case with manually and automatically delineated contours of the CTV on the external testing dataset are shown in Figure 4. Also, Figure 5 presents the CTV volumes of automatic and expert segmentations as the ground truth on the different views of CT images of 3 patients chosen randomly from the external testing dataset (n = 15).
Figure 3
Comparison of the volumes of the structure of interest (i.e. CTV) segmented manually and by the modified SegNet model
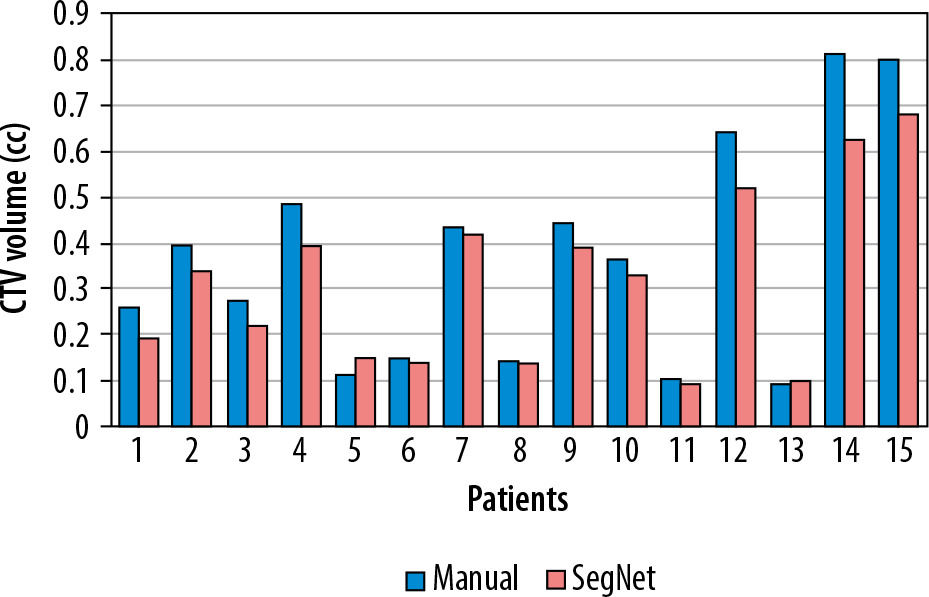
Figure 4
Examples of automatically generated contours (red) vs. ground truth (green) on axial view of T1cw magnetic resonance images of a representative case
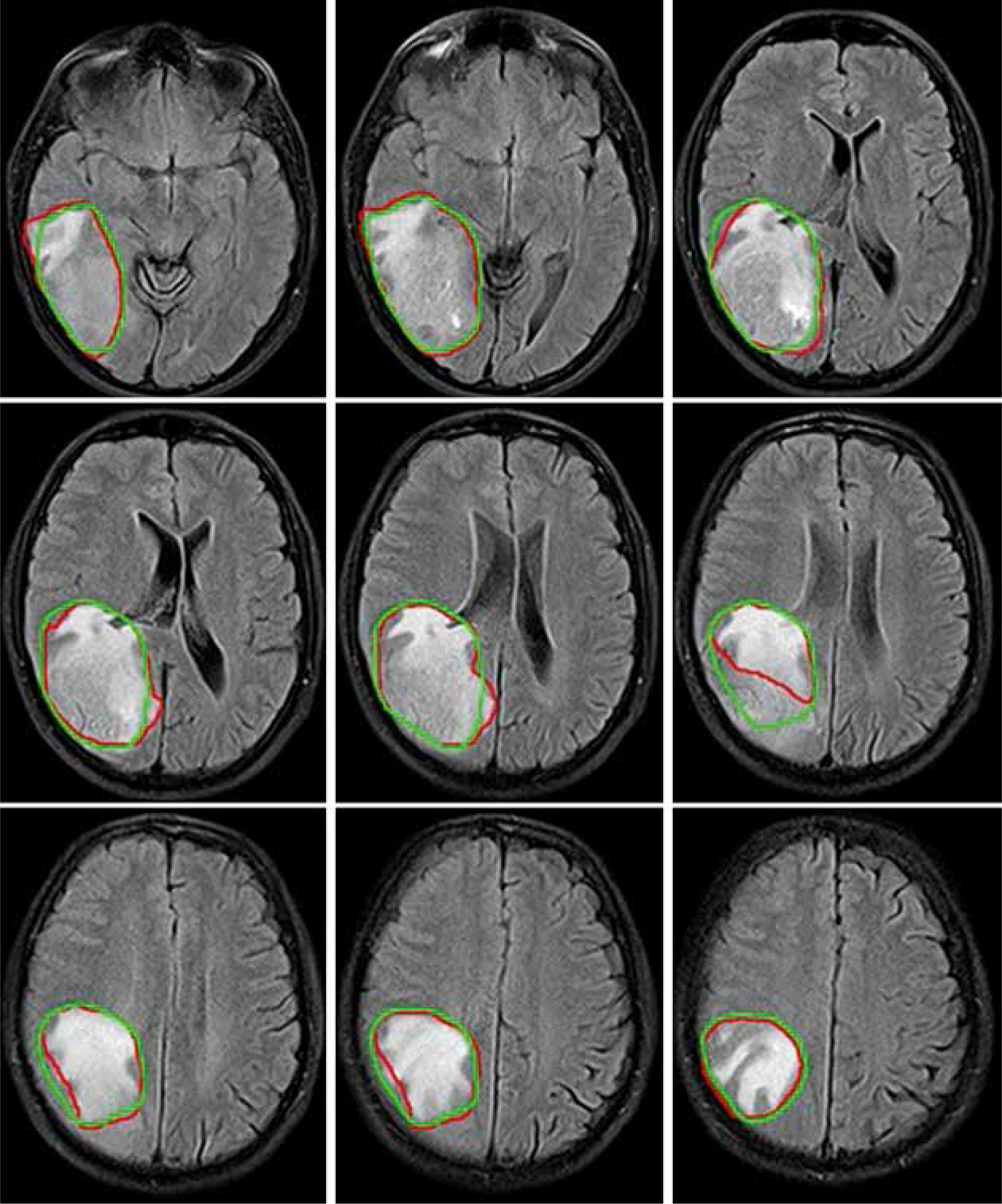
Figure 5
Axial, coronal, and sagittal (left to right) views of the contours generated with the SegNet model (red) and the ground truth (green) on computed tomography (CT) images of 3 representative cases
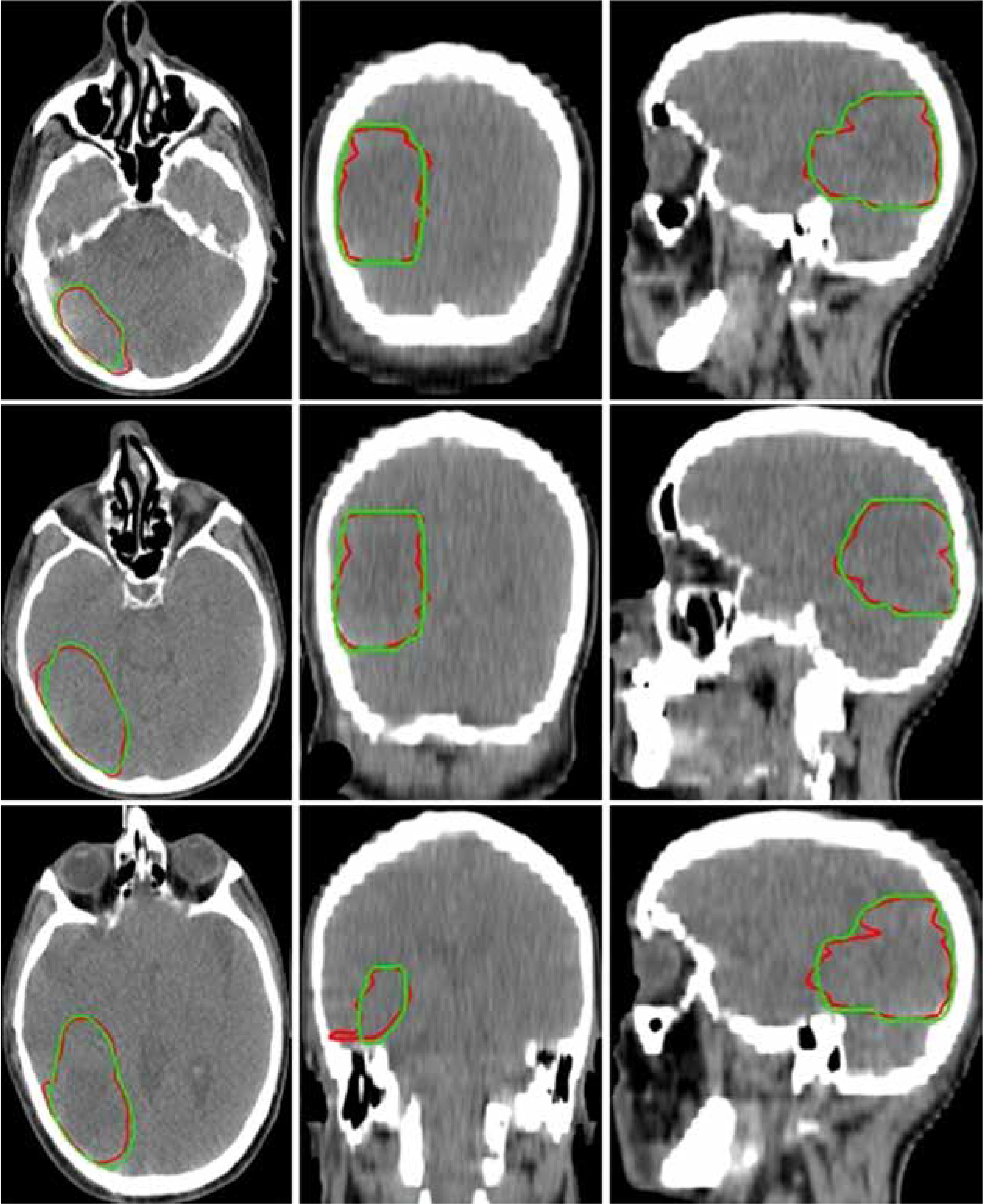
Table 1 summarizes the DSC and Hausdorff distance between manually and automatically delineated contours of the CTV on the 15 external CT scans. The mean ± SD DCS and Hausdorff distance were 89.6 ± 3.56 % and 1.49 ± 0.65 mm, respectively.
Table 1
The Dice similarity coefficients (in percentage) and Hausdorff distance (in mm) between the ground truth and the automatically generated contours on the clinical test set (n = 15)
| Patients | Dice similarity coefficient (%) | Hausdorff distance (mm) |
|---|---|---|
| 1 | 91 | 0.80 |
| 2 | 88 | 0.93 |
| 3 | 90 | 1.20 |
| 4 | 89 | 0.84 |
| 5 | 92 | 1.14 |
| 6 | 90 | 1.67 |
| 7 | 89 | 1.74 |
| 8 | 93 | 1.66 |
| 9 | 96 | 1.52 |
| 10 | 83 | 0.89 |
| 11 | 81 | 1.93 |
| 12 | 90 | 2.82 |
| 13 | 92 | 2.94 |
| 14 | 89 | 0.89 |
| 15 | 91 | 1.37 |
Table 2 lists the dosimetric parameters of the modified SegNet model and the manual contours for the clinical dataset. As shown in Table 2, a statistically significant difference was found for the Dmin and Dmax of different treatment plans based on manually and automatically delineated CTV, whereas there was no significant difference in the Dmean and D98% of the CTV.
Table 2
Comparison of the dose-volume parameters of the CTV for the automatically generated contours with the ground truth
| Dose-volume parameters | Manual | SegNet | p-value |
|---|---|---|---|
| Dmin (Gy) | 53.8 ± 5.19 | 49.3 ± 5.63 | 0.012* |
| Dmax (Gy) | 59.9 ± 7.28 | 65.6 ± 6.05 | 0.001* |
| Dmean (Gy) | 57.2 ± 6.11 | 58.9 ± 6.39 | 0.238 |
| D98% (Gy) | 55.8 ± 5.63 | 58.3 ± 6.02 | 0.097 |
Discussion
Contouring of target volume and OARs is known as a crucial step prior to radiotherapy treatment planning. It is well established that precise radiation treatment delivery depends heavily on accurate contouring of the target volume. The segmentation of glioblastoma tumours is difficult because of diffusion, poor contrast, and extension through the tentacle-like structures of these tumours [28]. In current clinical workflow, brain tumour segmentation is done manually, which is labour intensive and time-consuming. Moreover, slice-by-slice manual brain tumour delineation is prone to intra- and inter-rater variabilities. Hence, in this study, a CNN-based auto-segmentation model for the CTV delineation of glioblastoma tumours was trained and evaluated. Herein, the geometric and dosimetric uncertainties of the modified SegNet architecture as a deep CNN-based auto-contouring tool for radiotherapy of glioblastoma tumours were evaluated. We compared the performance of a deep-learning-based auto-segmentation system against retrospective contours drawn by an experienced radiation oncologist on data independent from the training dataset. From our results, it can be seen that the modified SegNet architecture can generate near-perfect contours for the CTV, as compared to expert segmentation (reference contour).
In this study, we trained the modified SegNet model on the BraTS 2019 training dataset for GTV segmentation of Glioblastoma tumours. Then, the pre-trained CNN model was fine-tuned with an independent clinical dataset to perform the CTV segmentation. In the process of fine-tuning, both CT and MRI scans were used as input data to provide a CT segmentation mask. Therefore, the value of our work lies in generating the predicted CT contour masks, which decreases CT/MRI image registration for the CTV contouring of Glioblastoma tumours, resulting in reduced contouring error. The proposed approach focuses on glioblastoma CTV segmentation on CT images based on guidance under MR images, because radiotherapy treatment planning is still mainly based on CT images in current clinical practice. Our method for the CTV delineation can be considered as an innovative and practical approach with promising results, especially in post-operative radiotherapy, because the GTV has been removed and the shape, appearance (e.g. the presence of oedema), and localization of glioblastoma tumours present remarkable variations, resulting in increasing intra- and inter-rater variability by manual segmentation.
From our data, it is evident that there is a similarity between CNN-based auto-segmented volumes and expert contours, as ground truth, with a DSC of 89.6%. Using the DSC, the performance of the modified SegNet network was comparable between our independent clinical dataset and the BraTS 2019 dataset, which achieved a Dice score for tumour core class of 88.0%. One reason for the relatively high Dice score lies in using aggressive data augmentation, which reduces false positives (i.e. the over-segmented volume in automatic segmentation contour but not included in manual segmentation), resulting in increasing the Dice score. All CTVs had a Hausdorff distance ≤ 2.94 mm, as shown in Table 1. Deep learning-based auto-segmented contours appear to have benefits over manual segmentation in terms of time-saving ability and mitigating inter-observer variability, as demonstrated in several studies [9,33,34]. Herein, the modified SegNet model has great potential to significantly decrease the radiation therapy planning time, as compared to manual contouring. It should be noted that even with the implementation of fully automated contouring systems in clinical practice, manual editing is still a necessity for patient safety.
Numerous research groups have trained and tested state-of-the-art brain tumour segmentation models on the BraTS datasets [23-26]. The performance of our model was comparable with previous studies in terms of DCS. Of note, previous studies generated the GTV of brain tumours, whereas the purpose of the present study was to automatically delineate the CTV contours of glioblastoma tumours. From a clinical point of view, the auto-generated CTV volumes cannot be compared to automated generation of a GTV. The GTV is defined based on medical image morphology, whereas the CTV is a medical decision and is constructed based on guidelines considering clinical experience and on tumour characteristics that are not quantifiable on imaging [14].
In the present study, we not only used the geometric metrics (i.e. DCS and Hausdorff distance) to evaluate segmentation approaches, but also assessed the dosimetric impact on deep learning-based auto-segmented structures versus radiation oncologist delineated structures. However, the goal of evaluating this CNN-based autosegmentation system is to apply it in radiotherapy treatment planning processes. In radiotherapy planning, the difference in the target volume may result in remarkable dosimetric discrepancies. In a previous study it was reported that even with volumetric differences between automatically and manually delineated volumes, dose-volume parameters computed using automated segmentations were comparable with the dosimetry based on manual segmentations as the ground truth [35]. Looking at Table 2, it is evident that although there was a significant difference between automatically constructed and reference volumes, we observed no significant difference in Dmean and D98% of the CTV between automatically constructed and reference volume planned doses. However, there was a significant difference in Dmin and Dmax of the CTV between manually and automatically planned doses.
A limitation of the present study was that the modified SegNet architecture was trained with a small number of subjects. Generally, deep leaning methods require a large amount of data for network training. Also, we evaluated deep leaning-based auto-segmented contours on a relatively small number of patients from a single centre. Using a larger cohort from multi-centre datasets may better assess the model’s robustness. Therefore, further study will be required to quantitatively compare deep leaning-based auto-segmented contours with manual contours from multi-centre independent datasets and determine the reproducibility of our segmentations. Taken together, our auto-contouring system can be considered as a supportive tool for radiation oncologists, resulting in significant benefits to radiotherapy planning workflow and resources. In other words, it is still necessary for radiation oncologists to review and edit the auto-generated contours to a clinically acceptable standard prior to treatment planning.
Conclusions
A deep learning approach for automatic segmentation of the CTV in glioblastoma patients has been evaluated. We demonstrated that the modified SegNet architecture can be applied successfully to brain tumour segmentation. The results of our study suggest that our CNN-based auto-contouring system can be used for segmentation of the CTVs to facilitate the brain tumour radiotherapy workflow. Our model has great potential to eliminate the need for CT/MRI image registration for the CTV delineation of glioblastoma tumours, which can result in reduced contouring error. The CNN-based auto-segmentation system can be integrated into a radiotherapy workflow, resulting in remarkably shortened contouring time. Although the auto-generated contours are inferior to manually delineated contours by a radiation oncologist, the results are promising.